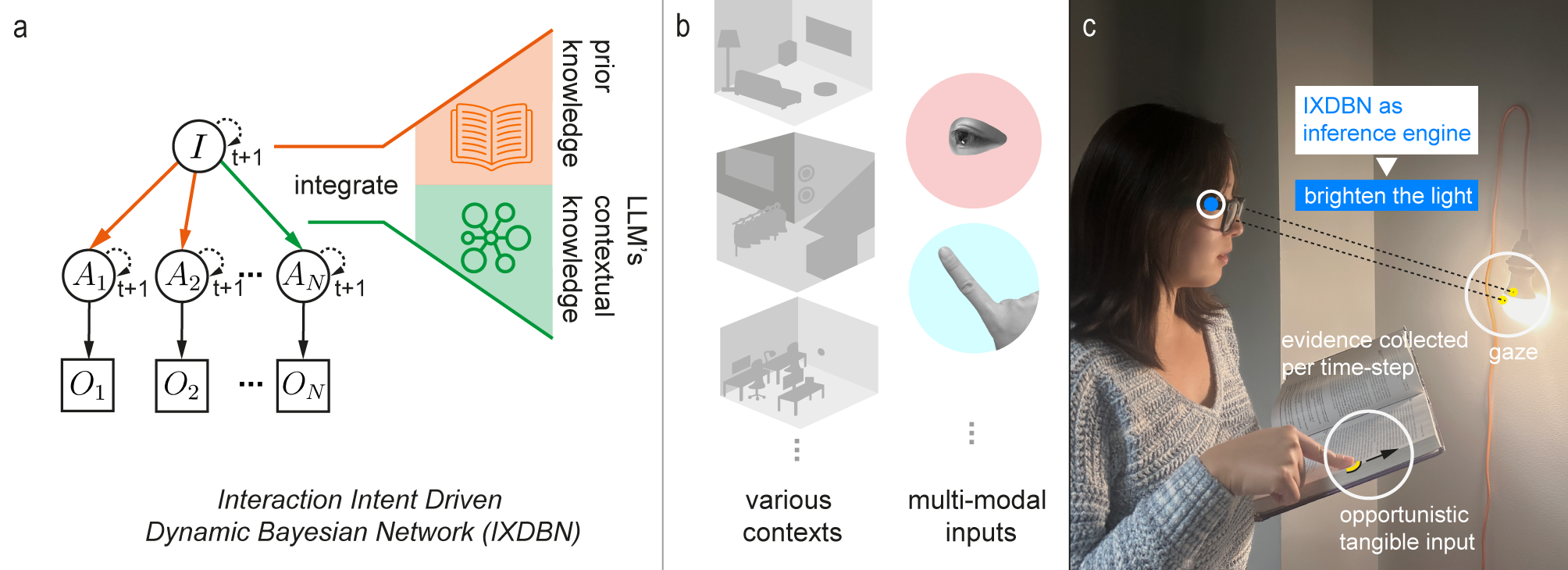
Multimodal context-aware interactions integrate multiple sensory inputs, such as gaze, gestures, speech, and environmental signals, to provide adaptive support across diverse user contexts. Building such systems is challenging due to the complexity of sensor fusion, real-time decision-making, and managing uncertainties from noisy inputs. To address these challenges, we propose a hybrid approach combining a dynamic Bayesian network (DBN) with a large language model (LLM). The DBN offers a probabilistic framework for modeling variables, relationships, and temporal dependencies, enabling robust, real-time inference of user intent, while the LLM incorporates world knowledge for contextual reasoning. We demonstrate our approach with a tri-level DBN implementation for tangible interactions, integrating gaze and hand actions to infer user intent in real time. A user evaluation with 10 participants in an everyday office scenario showed that our system can accurately and efficiently infer user intentions, achieving 0.83 per frame accuracy, even in complex environments. These results validate the effectiveness of the DBN+LLM framework for multimodal context-aware interactions.
Publication
Violet Yinuo Han, Tianyi Wang, Hyunsung Cho, Kashyap Todi, Ajoy Savio Fernandes, Andre Levi, Zheng Zhang, Tovi Grossman, Alexandra Ion, Tanya Jonker. 2025. A Dynamic Bayesian Network Based Framework for Multimodal Context-Aware Interactions. In Proceedings of IUI ’25. Cagliari, Italy. March 24 -27, 2025. DOI: https://dl.acm.org/doi/full/10.1145/3708359.3712070